Word2vec自编程实现。论文链接:
Efficient Estimation of Word Representations in Vector Space
Distributed Representations of Words and Phrases and their Compositionality
语言模型
LM 概念:语言模型时计算一个句子是句子(合乎语法,合乎语义 )的概率的模型。(LM一个重要应用:输入法)
语言模型的发展
- 基于专家知识的语法模型:语言学家企图总结出一套通用的语法规则,比如形容词后面接名词等。
- 统计语言模型:通过概率计算来刻画语言模型。

求解方法: 用语料的频率代替概率(频率学派)+ 条件概率
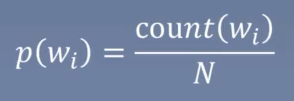
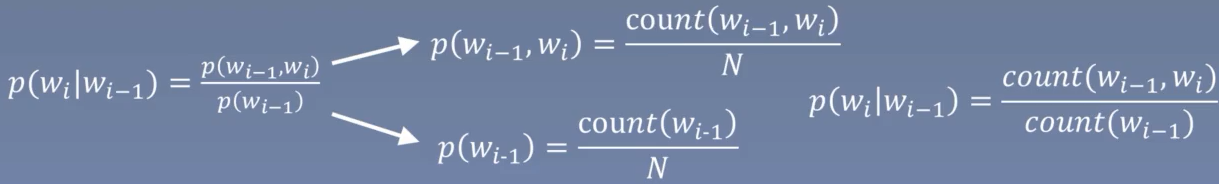
统计语言模型中的平滑操作:
有一些词或者词组在语料中没有出现过,但是这不能代表它不可能存在。平滑操作就是给没有出现过的词或者词组一个比较小的概率。
Laplace Smoothing,也称为加1平滑:每个词在原来出现次数的基础上加1。

平滑操作的问题:
- 参数空间过大 V+V^2+V^3+ … + V^n
- 数据稀疏严重: 经过平滑后,大部分都是极小且没用的参数。
马尔可夫假设:
下一个词的出现仅依赖于前面的一个词或几个词。
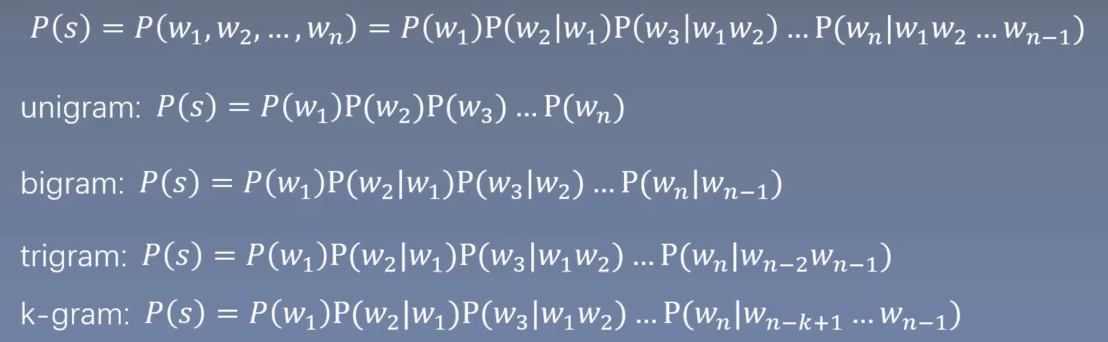
- 语言模型的评价指标:困惑度 (Perplexity)
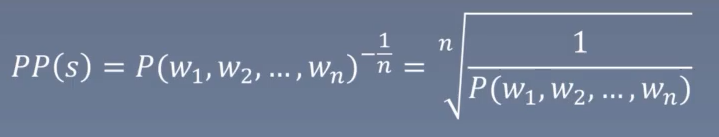
句子概率越大,语言模型越好,困惑度越小。