AUC的全称是Area Under ROC,及ROC曲线与坐标轴形成的面积,取值范围[0,1]。这个指标想要表达的含义,简单说是随机抽出一对样本(一个正样本,一个负样本),然后训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
AUC = P(P正样本>P负样本)
混淆矩阵定义
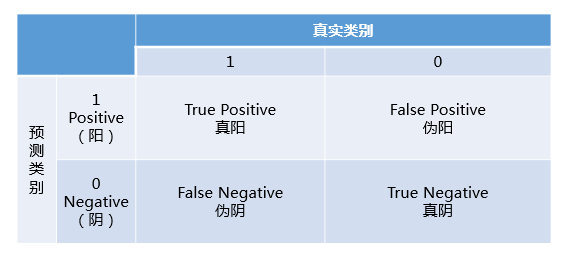
- TP: 将正类预测为正类数
- FN: 将正类预测为负类数
- FP: 将负类预测为正类数
- TN: 将负类预测为负类数
准确率,精确率,召回率,F1
准确率 (Accuracy):
ACC = ( TP+TN ) / (TP + TN + FP + FN),正负样本预测正确的个数与所有样本数的比值。精确率 (Precision):
Precision = TP / (TP + FP), 查准率,即所有预测为正中,真正为正的比例。召回率:
Recall = TP / (TP + FN),即所有正样本中,预测为正的比例(灵敏性、敏感性、查全率)。F1值:
2/F1 = 1/Precision + 1/Recall, 对Precision和Recall计算调和平均数。公式转化后为F1 = 2PR/(P + R) = 2TP/(2TP + FP + FN)。精确率和召回率都高的时候,F1也会高。Matthews correlation coefficient (MCC) [-1,+1]:
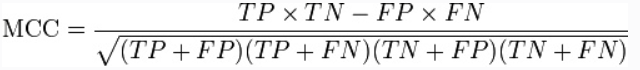
ROC曲线
ROC曲线是基于样本的真实类别和预测概率来画的,x轴是伪阳率(False Positive Rate)即在所有实际为负的样本中,预测为正的比率;y轴是真阳率(True Positive Rate)即在所有实际为正的样本中,预测为正的比率。
TPR = TP/P = TP/(TP + FN)FPR = FP/N = FP/(FP + TN)
给定不同阈值,可以计算出多组(X=FPR,Y=TPR)。我们希望分类器达到的效果是:对于真实类别为1的样本,分类器预测为1的概率(即TPRate),要大于真实类别为0而预测类别为1的概率(即FPRate),即y>x 。
AUC
AUC的计算方式
直接计算ROC曲线下面的面积。但这样做有个缺点,当多个测试样本的score相等时,调整阈值,得到的是一个斜向上的梯形,此时需要计算梯形的面积。比较麻烦。
分别随机从正负样本集中抽取一个正负样本,正样本的预测值大于负样本的概率。
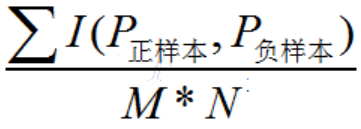
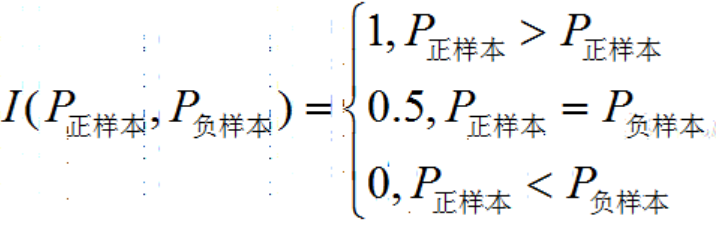
M,N分别为正样本数和负样本数,时间复杂度为O(n^2)。
- 第三种方式与第二种方式是一样的,但优化了复杂度。首先对score从小到大排序,最大score对应的样本的rank为n,第二大为n-1,以此类推。然后将所有正样本的rank相加,再减去M-1种两个正样本组合的情况。rank n 与前n-1组合,有M-1是正样本。为简便计算,取n组,相应的不符合为M。
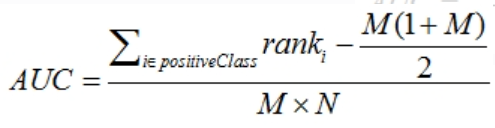
当score相等时,需要对这些score相等的样本的rank取平均,然后再使用上述公式。
AUC的优势
AUC的计算方法同时考虑分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。
例如在反欺诈场景,设欺诈类样本为正例,正例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为负例,便可以获得99.9%的准确率。
但是如果使用AUC,把所有样本预测为负例,TPRate和FPRate同时为0(没有Positive),与 (0,0) 和 (1,1)连接,得出AUC仅为0.5,成功规避了样本不均匀带来的问题。
AUC的局限性
AUC作为排序的评价指标本身具有一定的局限性,它衡量的是整体样本间的排序能力,对于计算广告领域来说,它衡量的是不同用户对不同广告之间的排序能力,而线上环境往往需要关注同一个用户的不同广告之间的排序能力。阿里在 [Deep Interest Network] 种提到一种改进的AUC指标,用户加权平均AUC,更能反映线上真实环境的排序能力。
gAUC(group auc)
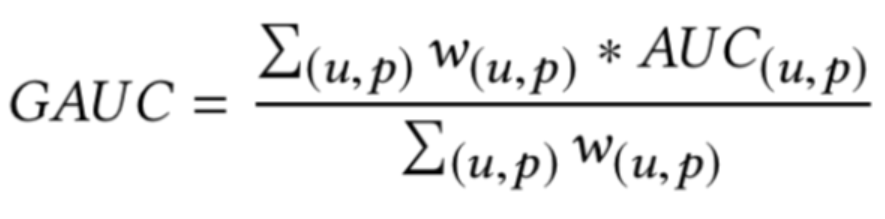
实际处理时权重一般可以设为每个用户view或click的次数,而且会过滤掉单个用户全是正样本或负样本的情况。
PR曲线
x轴Recall,y轴Precision。
AUPR:PR曲线下面积。