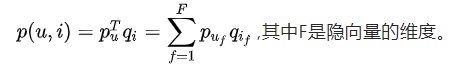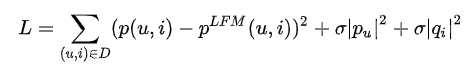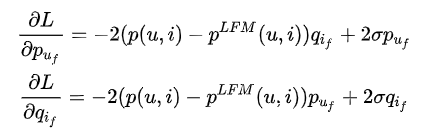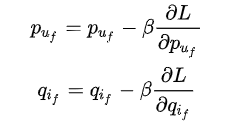1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
"""
author: fivelike
date: 2021.5.17
util function
"""
import os
def get_item_info(input_file):
"""
get item info: [title, genre]
:param input_file: item info file
:return:
a dict: key: itemid, value: [title, genre]
"""
if not os.path.exists(input_file):
return {}
item_info = {}
linenum = 0
fp = open(input_file, encoding="utf-8")
for line in fp:
if linenum == 0:
linenum += 1
continue
item = line.strip().split(',')
if len(item) < 3:
continue
elif len(item) == 3:
itemid, title, genre = item[0], item[1], item[2]
elif len(item) > 3:
itemid = item[0]
genre = item[-1]
title = ",".join(item[1: -1])
item_info[itemid] = [title,genre]
fp.close()
return item_info
def get_ave_score(input_file):
"""
get item ave rating score
:param input_file: user rating file
:return:
a dict: key: itemid, value: ave_score
"""
if not os.path.exists(input_file):
return {}
linenum = 0
record_dict = {}
score_dict = {}
fp = open(input_file, encoding="utf-8")
for line in fp:
if linenum == 0:
linenum += 1
continue
item = line.strip().split(',')
if len(item) < 4:
continue
userid, itemid, rating = item[0], item[1], float(item[2])
if itemid not in record_dict:
record_dict[itemid] = [0,0]
record_dict[itemid][0]+=1
record_dict[itemid][1]+=rating
fp.close()
for itemid in record_dict:
score_dict[itemid] = round(record_dict[itemid][1]/record_dict[itemid][0],3)
return score_dict
def get_train_data(input_file):
"""
get train_data for LFM model
:param input_file: user_item_rating file
:return:
a list: [(userid, itemid, label)]
"""
if not os.path.exists(input_file):
return []
score_dict = get_ave_score(input_file)
neg_dict = {}
pos_dict = {}
train_data = []
linenum=0
score_thr = 4.0
fp = open(input_file, encoding="utf-8")
for line in fp:
line = line.replace('\n','')
if linenum==0:
linenum+=1
continue
item = line.strip().split(',')
if len(item)<4:
continue
userid, itemid, rating = item[0],item[1], float(item[2])
if userid not in pos_dict:
pos_dict[userid] = []
if userid not in neg_dict:
neg_dict[userid] = []
if rating >= score_thr:
pos_dict[userid].append((itemid,1))
else:
score = score_dict.get(itemid,0)
neg_dict[userid].append((itemid, score))
fp.close()
for userid in pos_dict:
data_num = min(len(pos_dict[userid]), len(neg_dict.get(userid, [])))
if data_num>0:
train_data += [(userid, co[0], co[1]) for co in pos_dict[userid]][:data_num]
else:
continue
sorted_neg_list = sorted(neg_dict[userid], key=lambda element:element[1], reverse=True)[:data_num]
train_data += [(userid, co[0], 0) for co in sorted_neg_list]
return train_data
|